Introduction
Hi ! Today we are going to talk about API hashing, something you have probably came across multiple times when reverse engineering malwares. I’m going to show you how we can implement API hashing, detect it, and bypass it !
Usually one of the first thing you do when analyzing a binary is taking a look at the PE Import Table, letting you know what possible functionalities the sample has (is it doing some networking, file handling, process injection, modifying registry keys, unpacking …?). For this reason, a threat actor really wants to obfuscate his product, making it more difficult to analyze…
This is where API hashing appears. Let’s take a look at a simple binary I made to demonstrate the technique.
The Analyst’s View
Let’s look at the import table of the sample and see what we can learn about the executable:
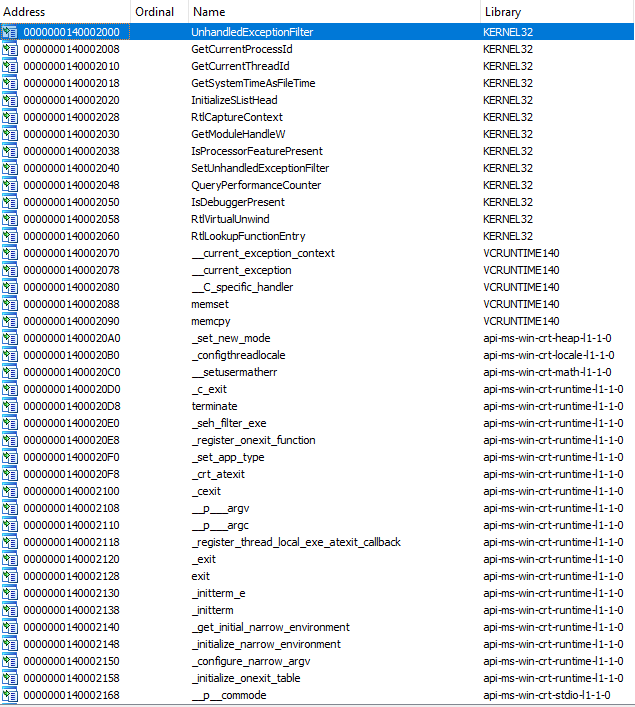
mmmh…We do not see anything interesting in this table…The imports listed here are just used to generate a stack cookie and initializing the Microsoft C Runtime Library (search “scrt_commain_main_seh” if you want to learn more about that).
If we run the executable (it is not malicious :D), it drops a file named "demo.txt", yet we did not see any CreateFile/WriteFile or any lower level equivalent API call. How is this possible..? Keep digging in the main function which is pretty straight forward:
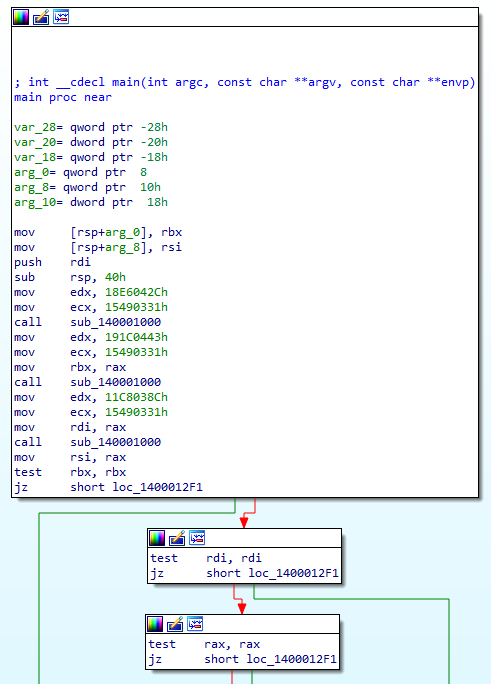
It calls sub_140001000 with two integers as arguments three times and check that the return values (rbx, rdi, rsi) are not null else it exits.
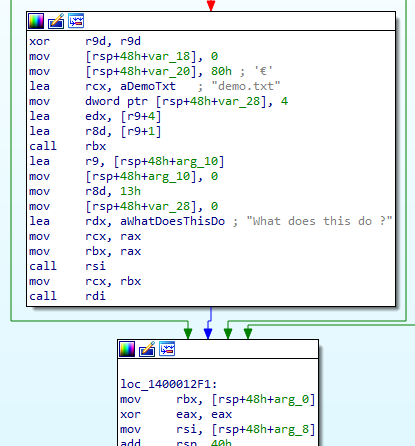
If none of them return 0, it will call the values returned by the function (rbx, rdi, rsi), then exits. The disassembly can be translated to the pseudocode:
main()
{
v1 = sub_140001000(0x15490331, 0x18E6042C);
v2 = sub_140001000(0x15490331, 0x191C0443);
v3 = sub_140001000(0x15490331, 0x11C8038C);
if (v1 && v2 && v3)
{
v4 = v1("demo.txt", 4, 1);
v5 = 0;
v2(v4, "What does this do ?", 19, &v5, 0);
v3(v4);
}
}
We guess from the behavior of the program that and arguments that v1 is the function opening the file, v2 writes to it and v3 closes it.
This means that the malware is doing some kind of dynamic API resolving (retrieving the functions at runtime), the value 0x15490331 probably being the hash of a module name, and the second arguments the hash of a function name.
Theory
Before seeing from the malware developer’s view to explain the implementation, a little theory on what you need to know before understanding API hashing is recommended.
1- The Process Environment Block
Wikipedia defines it well:
The Process Environment Block (abrreviated PEB) is a data structure in the Windows NT operating system family. It is an opaque data structure that is used by the operating system internally, most of whose fields are not intended for use by anything other than the operating system. […] The PEB contains data structures that apply across a whole process, including global context, startup parameters, data structures for the program image loader, the program image base address….
The PEB basically stores information about a running process, the 64-bit version of the structure is poorly documented by Microsoft (though it has been fully reversed for multiple kernel versions):
typedef struct _PEB {
BYTE Reserved1[2];
BYTE BeingDebugged;
BYTE Reserved2[21];
PPEB_LDR_DATA LoaderData;
PRTL_USER_PROCESS_PARAMETERS ProcessParameters;
BYTE Reserved3[520];
PPS_POST_PROCESS_INIT_ROUTINE PostProcessInitRoutine;
BYTE Reserved4[136];
ULONG SessionId;
} PEB;
There are a lot of interesting fields in this structure we could talk about, but what we are interested in right now is the LoaderData field, which holds a linked list of modules loaded for the process.
You can access the PEB through an assembly stub or an intrinsic function only, on Windows for the x64 architecture, a pointer to the PEB is located at offset 0x60 in the GS segment:
reinterpret_cast<PNT_PEB64>(__readgsqword(0x60));
mov rax, qword ptr gs:[60]
2 - Hashing
Hashing is the process of transforming input data into a fixed-size value, called a “hash” or a “digest”. The two key characteristics that are really important for our use-case is that it is:
- Deterministic: Hashing the same input will always give the same digest, which is important for comparisons. Mathematically: \(h(x_1) = h(x_2) \iff x_1 = x_2\)
Although in practice, depending on the algorithm, collisions may happen more or less meaning: \(h(x_1) = h(x_2) \land x_1 \neq x_2\)
- Irreversibility: Hashing functions are one-way, you can not find the input from the output without bruteforcing with all possible inputs. This is important for the malware developer, it’s not some xor string cyphering.
3 - The PE Export Table
The PE Export Table (or Export Directory) is a data structure contained inside PE files (mainly DLLs). It basically holds a table of functions that can be accessed by other modules. It is defined as:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
The field AddressOfFunctions is essentially the EAT (Export Address Table).
When you load a procedure from a DLL with the famous function GetProcAddress, it will simply walk through the EAT of the module, compare the function names and return the function’s address.
The Malware Developer’s View
We will now walk through the original source of the executable to put it all together and see how this is done. Here is the main function of the sample we looked at in IDA:
int main(int argc, char** argv)
{
constexpr auto DigestModule = SymHash(L"KERNEL32.DLL");
constexpr auto DigestCreateFileW = SymHash("CreateFileW");
constexpr auto DigestCloseHandle = SymHash("CloseHandle");
constexpr auto DigestWriteFile = SymHash("WriteFile");
const auto CreateFileW = ResolveAPI<pCreateFileW>(DigestModule, DigestCreateFileW);
const auto CloseHandle = ResolveAPI<pCloseHandle>(DigestModule, DigestCloseHandle);
const auto WriteFile = ResolveAPI<pWriteFile>(DigestModule, DigestWriteFile);
if (CreateFileW && CloseHandle && WriteFile)
{
HANDLE FileHandle = CreateFileW(L"demo.txt",
FILE_APPEND_DATA,
FILE_SHARE_READ,
nullptr,
OPEN_ALWAYS,
FILE_ATTRIBUTE_NORMAL,
nullptr);
DWORD dwBytesWritten {};
WriteFile(FileHandle, "What does this do ?", 19, &dwBytesWritten, nullptr);
CloseHandle(FileHandle);
}
return 0;
}
First, the malware calculates the hashes of the symbols that we wish to use, it uses the quite convenient C++ keyword constexpr which suggests the compiler to evaluate code at compile time.
That way, the malware developer still has the symbols that where hashed but they won’t appear in the binary.
In our case, the SymHash function is just a simple Adler-32 hash implementation, it takes a string as input and returns a 4 bytes integer.
// Make a template because module names are stored as wide strings in the PEB
// and we want to be able to use normal strings for convenience
template<typename char_type>
constexpr uint32_t SymHash(char_type* Symbol)
{
// Adler32 hash implementation
constexpr uint16_t MOD_ADLER = 0xFFF1;
uint32_t csum1 = 1;
uint32_t csum2 = 0;
for (const char_type c : std::basic_string_view<char_type>(Symbol))
{
csum1 = (csum1 + c) % MOD_ADLER;
csum2 = (csum2 + csum1) % MOD_ADLER;
}
return (csum2 << 16) | csum1;
}
The important part is the ResolveAPI function:
template<typename Function>
Function ResolveAPI(uint32_t ModuleHash, uint32_t ProcedureHash)
{
NT_LDR_DATA_TABLE_ENTRY* const Module = ResolveInMemoryModule(ModuleHash);
if (!Module)
return nullptr;
void* Proc = ResolveProcedure((LPBYTE)Module->DllBase, ProcedureHash);
if (Proc == nullptr)
return nullptr;
return reinterpret_cast<Function>(Proc);
}
It will call ResolveInMemoryModule which will search for a certain module in the PEB, known as PEB walking, think of it as the equivalent of LoadLibrary, but the library is already loaded:
PNT_LDR_DATA_TABLE_ENTRY ResolveInMemoryModule(uint32_t ModuleHash)
{
const auto Peb = NtCurrentPeb();
const auto LoaderData = Peb->Ldr;
// circular doubled linked list of all modules loaded for the process.
// each item in the list is a pointer to an LDR_DATA_TABLE_ENTRY structure
const LIST_ENTRY* Head = &LoaderData->InMemoryOrderModuleList;
const LIST_ENTRY* ModuleNode = nullptr;
// walk through the list
for (ModuleNode = Head->Flink; ModuleNode != Head ; ModuleNode = ModuleNode->Flink)
{
// CONTAINING_RECORD is a weird macro hack from microsoft
// to retrieve a pointer to a structure containing a specific field.
const auto LoadedModule = CONTAINING_RECORD(ModuleNode, NT_LDR_DATA_TABLE_ENTRY, InMemoryOrderModuleList);
const auto ModuleName = LoadedModule->BaseDllName.Buffer;
// if name digest correspond this means
// the entry is the module we want to retrieve
if (SymHash(ModuleName) == ModuleHash)
return LoadedModule;
}
return nullptr;
}
We compare each hash with the hash we are looking for.
After we have found a handle to the module we want, we can access the field DllBase of the returned LDR_DATA_TABLE_ENTRY which points to the loaded DLL Image
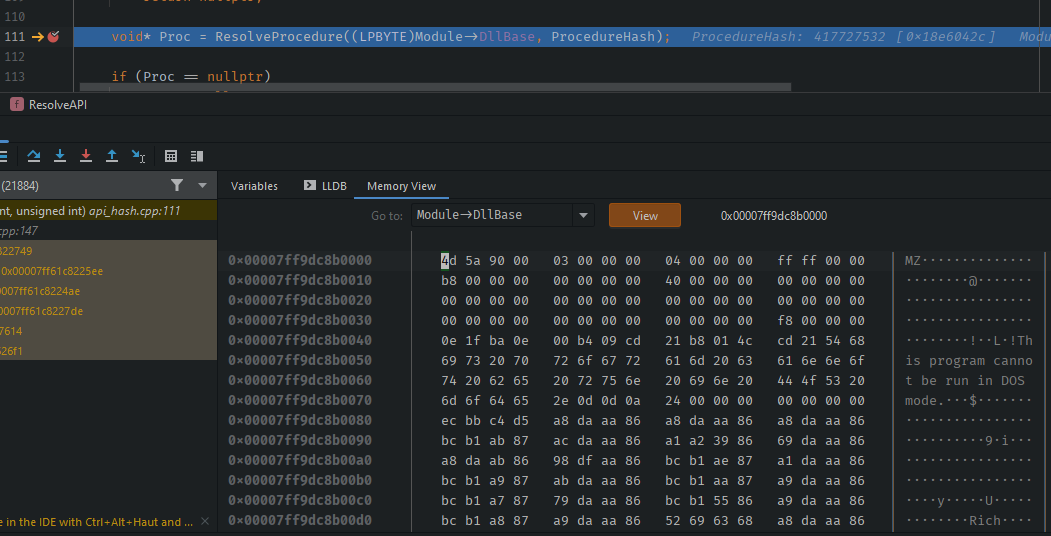
Next we call ResolveProcedure(LPBYTE ModuleBase, uint32_t ProcedureHash), which is a custom reimplementation of GetProcAddress(HMODULE Mod, LPCSTR lpProcName) that takes the hash of lpProcName calculated at compile time instead:
LPVOID ResolveProcedure(LPBYTE ImageBase, uint32_t ProcedureHash)
{
const auto DosHdr = (PIMAGE_DOS_HEADER)ImageBase;
if (DosHdr->e_magic != IMAGE_DOS_SIGNATURE)
return nullptr;
const auto NtHdrs = (PIMAGE_NT_HEADERS64)(ImageBase + DosHdr->e_lfanew);
auto VerifyImage = [](auto NtHeaders) -> bool
{
if (NtHeaders->Signature != IMAGE_NT_SIGNATURE)
return false;
if ((NtHeaders->FileHeader.Characteristics & IMAGE_FILE_DLL) == 0)
return false;
const auto DirSize = NtHeaders->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].Size;
const auto DirVirt = NtHeaders->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress;
if (DirSize == 0 || DirVirt == 0)
return false;
return true;
};
// Verify that there is a export directory.
if (!VerifyImage(NtHdrs))
return nullptr;
const auto& OptHdr = NtHdrs->OptionalHeader;
const auto ExportDirVirt = OptHdr.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress; // actually a RVA
const auto ExportDir = (PIMAGE_EXPORT_DIRECTORY)(ImageBase + ExportDirVirt);
// Get the EAT
const auto Ordinals = (LPWORD) (ImageBase + ExportDir->AddressOfNameOrdinals);
const auto Functions = (LPDWORD)(ImageBase + ExportDir->AddressOfFunctions);
const auto Symbols = (LPDWORD)(ImageBase + ExportDir->AddressOfNames);
// For each entry in the EAT
for (size_t i = 0; i < ExportDir->NumberOfNames; ++i)
{
// Retrieve the exported function name
const char* SymName = (char*)(ImageBase + Symbols[i]);
// Return function address if the hashes match
if (SymHash(SymName) == ProcedureHash)
return (LPVOID)(ImageBase + Functions[Ordinals[i]]);
}
return nullptr;
}
Detection of API hashing
Now that we know how API hashing works and can be implemented, we are easily able to detect it from inside a disassembler/decompiler.
-
Few to no imports (except the default ones as we saw earlier). This quite probably means that functions are being resolved at runtime, if you can not find xrefs to LoadLibrary/GetProcAddress, this probably means that the malware is going to scan for those in the PEB’s module list. If there are references to those two APIs, probably the symbols names are just being decrypted at runtime.
-
Lots of function pointers as it is done for usual dynamic API resolving. You should also see a lot of calls looking like this:
ptr1 = sub_XXXX(0xDEADBEEF, 0x1337);
ptr2 = sub_XXXX(0xDEADBEEF, 0xCAFE);
ptr3 = sub_XXXX(0xDEADBEEF, 0xBABE);
ptr1(1, 2, 3);
ptr2();
ptr1(4, 5);
With two integers passed as argument, 0xDEADBEEF being the hash of a module’s name, and 0x1337 being the hash of a procedure’s name.
-
mov rax, qword ptr gs:[60] / NtCurrentPeb(). The malware is retrieving the Process Environment Block. Note that IDA automatically replaces the assembly by NtCurrentPeb() in the decompilation view, this is not a WinAPI function.
-
PEB walking. The malware retrieves the module by traversing one of the three linked lists in the PEB_LDR_DATA structure:
struct NT_PEB_LDR_DATA
{
DWORD Length;
DWORD Initialized;
LPVOID SsHandle;
LIST_ENTRY InLoadOrderModuleList;
LIST_ENTRY InMemoryOrderModuleList;
LIST_ENTRY InInitializationOrderModuleList;
LPVOID EntryInProgress;
};
IDA has no problem typing the local variables correctly, making it easy to detect.
- PE Parsing, once the malware retrieved the base address of the module it wants, it needs to parse the module to obtain its EAT.
If you need, you can use IDA’s immediate value search to search for the DOS Header Magic (0x5A4D) or the PE signature (0x4550) which the malware might check for.
If you want to label and type the PE structures, make sure to use the right version of the structures for 32-bit or 64-bit PE format !
- Presence of a hash function called during PEB walking and PE parsing. In our case:
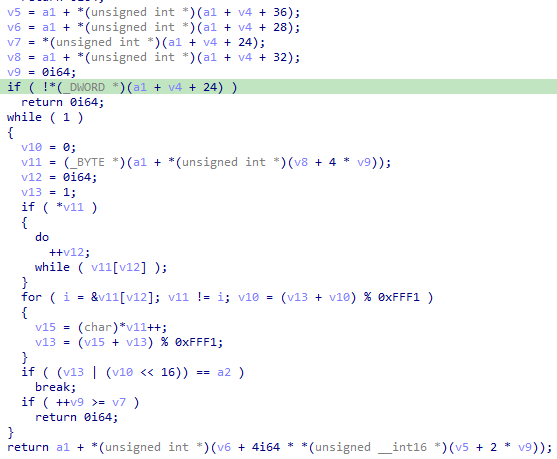
Bypassing it
Alright that’s cool now we can detect it and reverse engineer it easily. But we have a problem…We still have no idea what functions the malware is importing…As I said, hashing is not reversible so we can’t expect to just directly decrypt some symbols.
There are two ways we can find what the malware is importing dynamically.
Debugging
We can put breakpoints where the malware is comparing the digests when it is looking at the PEB module list.
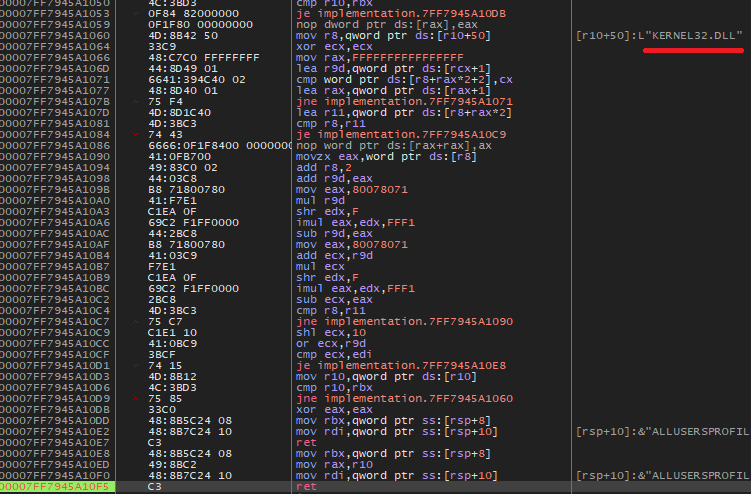
Here I put a breakpoint where the function that resolve the in memory module via the PEB returns a valid pointer (no xor eax, eax). We can see that the malware is trying to resolve KERNEL32.DLL, exactly as we saw from the source.
We can also set breakpoints where it is resolving procedure from the EAT the same way.
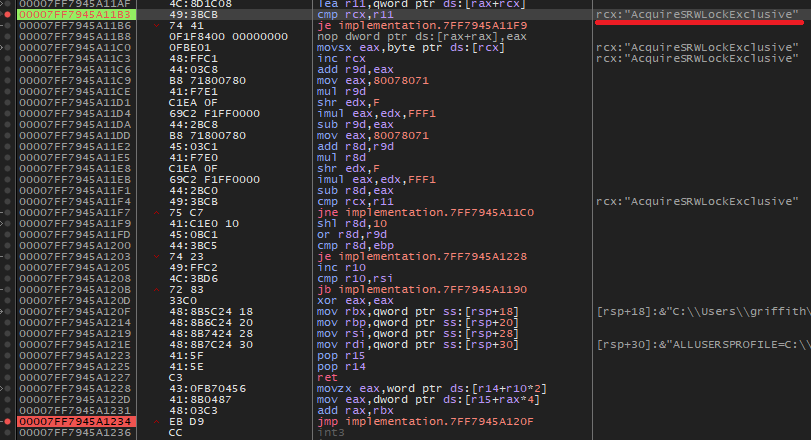
Insert a breakpoint before the digest of the symbol is computed, allowing us to see what symbol is being compared. It is not of big use because the breakpoint is going to be hit a thousand times.
Most importantly set a second breakpoint where the function returns a valid pointer from the EAT (no xor eax, eax).

Conveniently, x64dbg automatically compares addresses and find which function was dynamically resolved. Here it tries to load CreateFileW from kernel32.dll, as we saw from the source.
Bruteforcing the hash
As explained before, a hash function is one way, so we would need to bruteforce the hash function with all possible WinAPI exports. I made a C++ tool that you can find here, allowing us to automate this, you feed it some DLLs and it will dump their exported function names. It is pretty fast as I multithreaded it, so you can pass lots of DLLs to increase chances to find a matching hash. You can also conveniently pass it a python function so it automatically computes the hashes and builds a hashtable.

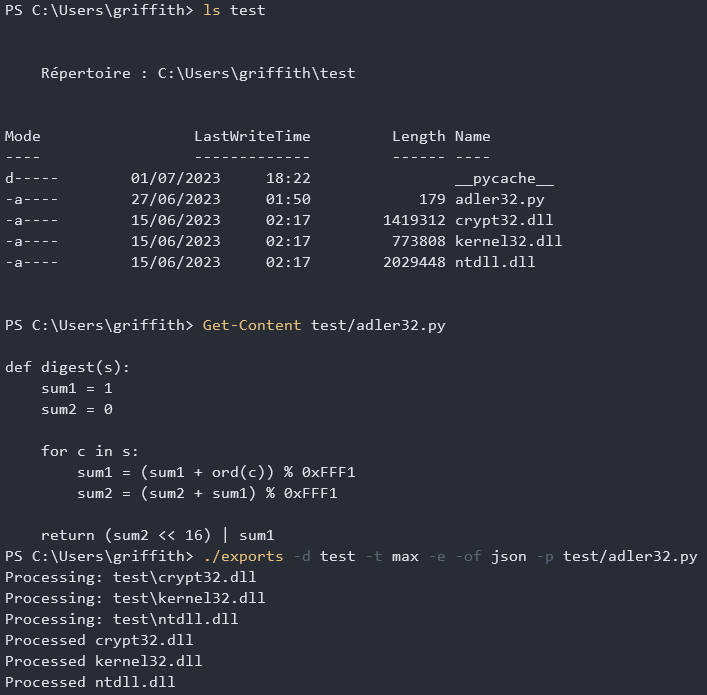
It now created a hashtable for us, we just need to search for the digests we have in IDA, in our case they were 18E6042C, 191C0443, and 11C8038C. Looking at our hashtable they map to CreateFileW, CloseHandle, and WriteFile, as we saw from the original code. Perfect, we can now label everything in our IDB and start reversing !
Conclusion
Here is what you need to know about API hashing, if you want to experiment find the source code for the implementation of API hashing here.